Fine-Tuning Agent Setup
Fine-tuning creates an agent trained specifically on your product’s data. This setup provides the highest accuracy and can optionally use RAG for knowledge-grounded responses.
🧠 Overview
The fine-tuning form allows you to:
- Configure training data selection
- Adjust advanced training parameters
- Monitor estimated cost
- Optionally enable RAG for hybrid performance
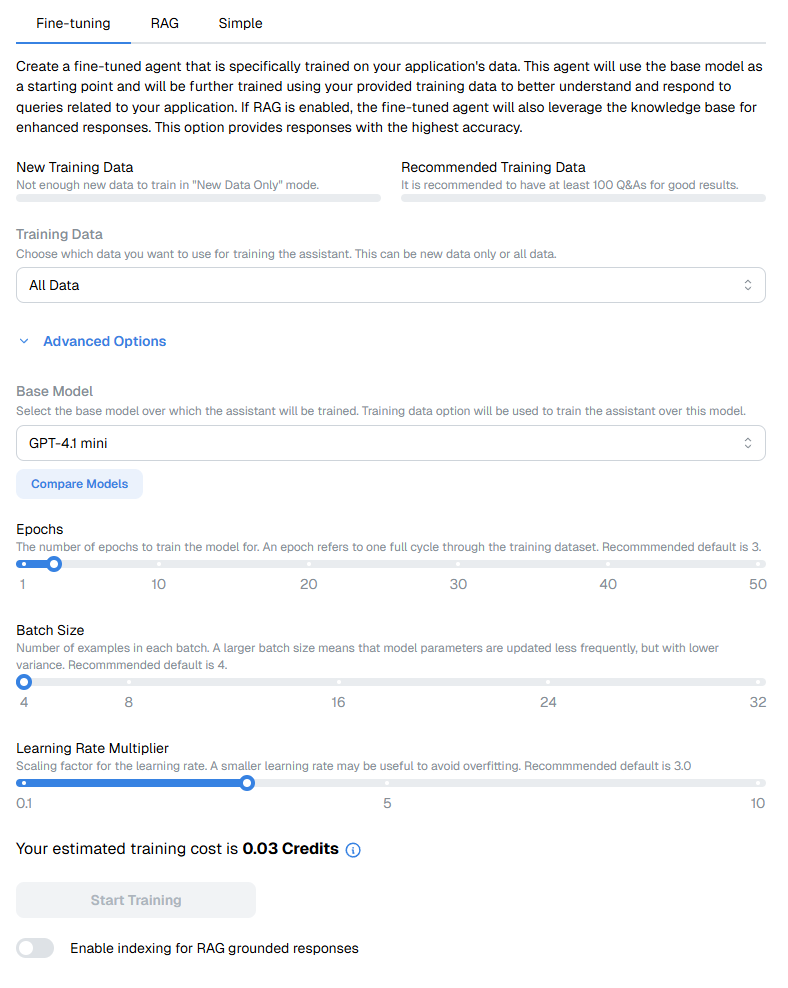
🧾 Form Fields
New Training Data
Shows whether enough new (unfrozen) Q&As exist for training in “New Data Only” mode.
Tip: It’s recommended to have at least 100 Q&As for reliable results.
Training Data
Choose which Q&As to include in training:
- New Data Only - only unfrozen Q&As
- All Data - combines new and frozen Q&As
Advanced Options
Expand to access fine-tuning parameters:
| Field | Description | Recommended Default |
|---|---|---|
| Base Model | The foundation model to fine-tune (e.g., GPT-4.1 mini). | Last trained or GPT-4.1 mini |
| Epochs | Number of passes through the training dataset. | 3 |
| Batch Size | Number of examples processed per batch. | 4 |
| Learning Rate Multiplier | Controls how aggressively weights are updated. | 3.0 |
⚙️ Use “Compare Models” to view details of available base models.
💰 Estimated Training Cost
Shows a live estimate of training cost in credits based on dataset size and augmentation. Actual costs may vary slightly depending on system-level optimizations.
🧩 RAG Integration
Toggle “Enable indexing for RAG grounded responses” to combine fine-tuning with RAG. This allows your model to reference your knowledge base dynamically during inference.
🧠 Tip: RAG can be enabled at any stage - even after fine-tuning - so you can add grounding later if needed.
▶️ Start Training
Once configured, click Start Training to queue your fine-tuning job. The Training Timeline on the right shows:
- Queued → preparing data
- Training → in progress
- Completed → ready to use